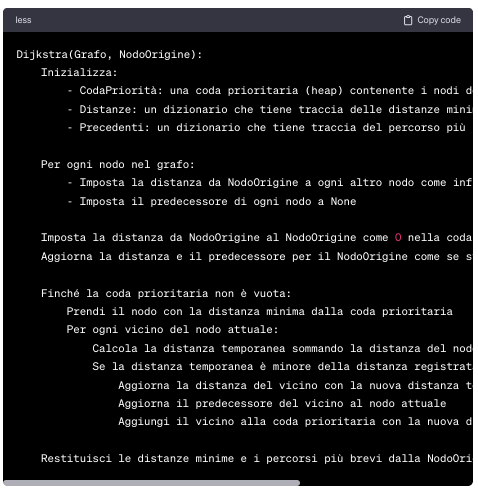
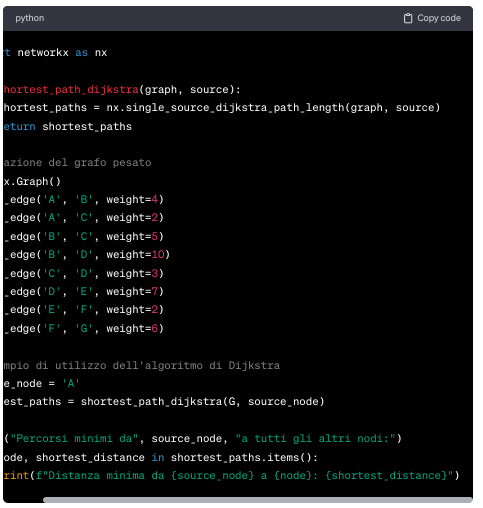
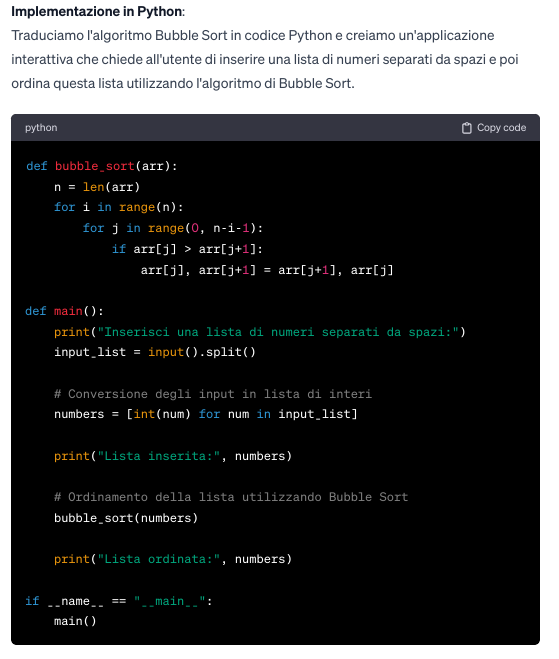
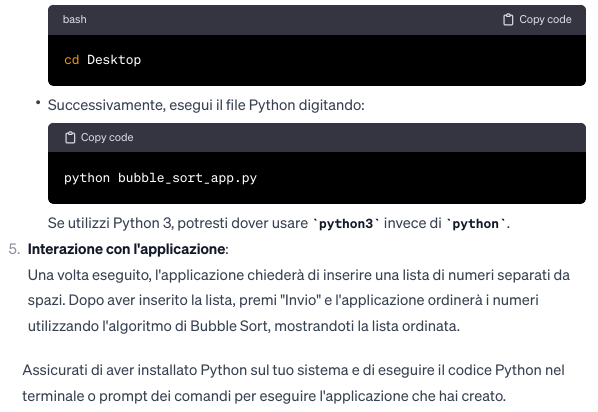
16. Traduzione algoritmo di DijkStra in una applicazione

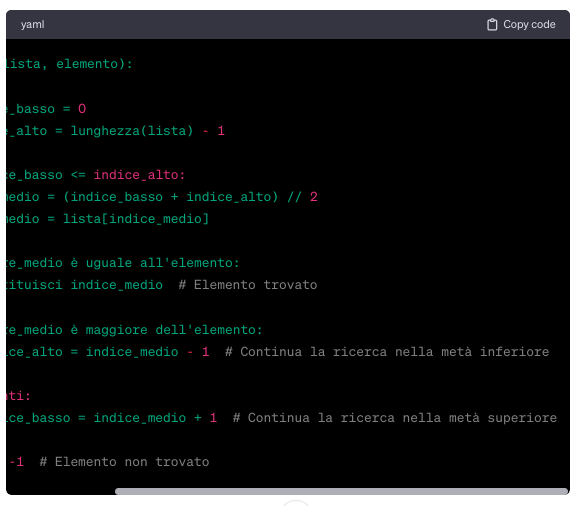
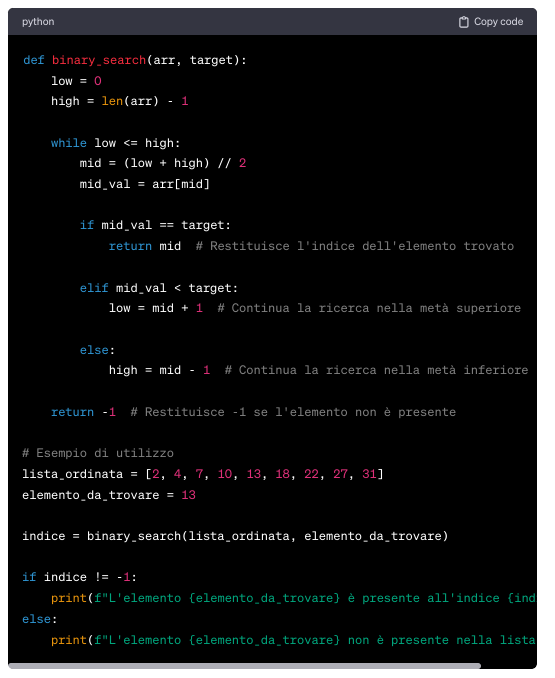
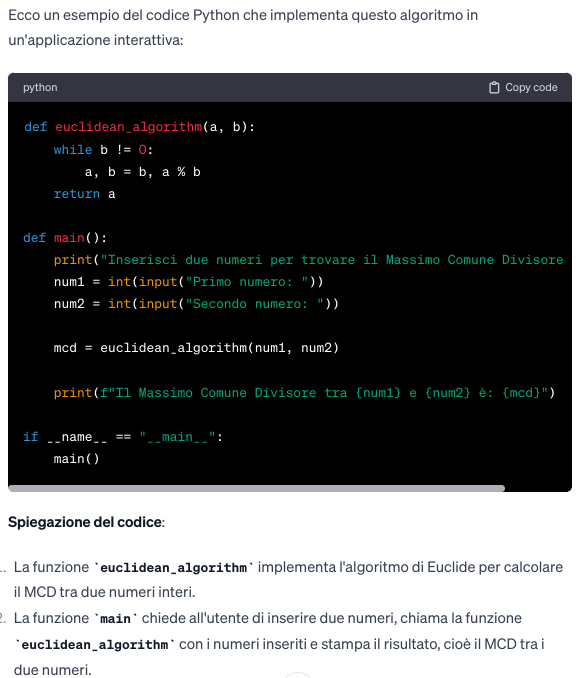
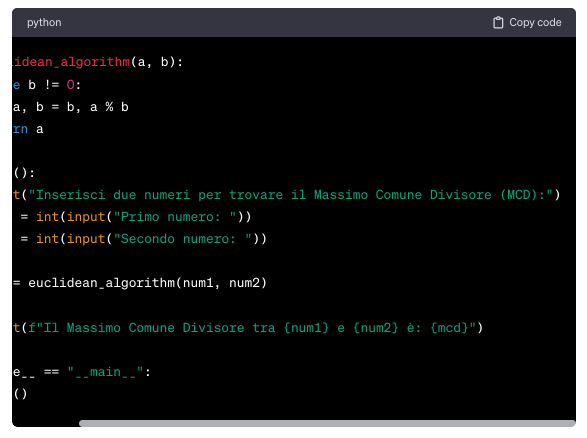
15. Traduzione algoritmo di ricerca binaria in una applicazione
.png)
.png)
Gli algoritmi paralleli sono progettati per sfruttare la capacità di elaborazione di più processori o core contemporaneamente al fine di risolvere problemi in modo più efficiente. Questi algoritmi dividono spesso il carico di lavoro in sottoparti che possono essere eseguite simultaneamente su differenti unità di elaborazione, consentendo una maggiore velocità di calcolo e una gestione più efficiente delle risorse di elaborazione disponibili.
Ci sono diversi approcci per progettare algoritmi paralleli:
12.1-Parallelismo dei dati: L'elaborazione parallela di grandi quantità di dati suddivisi tra i processori. Ad esempio, in un'operazione di somma di array, diversi processori possono sommare parti diverse degli array contemporaneamente.
Il parallelismo dei dati coinvolge l'elaborazione simultanea di diversi pezzi di dati utilizzando più risorse di calcolo. Un esempio comune di parallelismo dei dati è l'elaborazione di un'operazione su una grande quantità di dati dividendo il lavoro tra più processi o thread.
Qui di seguito un semplice esempio di parallelismo dei dati utilizzando il modulo multiprocessing in Python per calcolare la radice quadrata di una serie di numeri:
python
Copy code
import multiprocessing
import math
# Funzione che calcola la radice quadrata di una serie di numeri
def square_root(numbers, result, index):
for i, num in enumerate(numbers):
result[index + i] = math.sqrt(num)
if __name__ == "__main__":
# Lista di numeri di esempio
numbers_to_process = [x for x in range(1, 1000001)]
# Numero di processi paralleli da utilizzare
num_processes = multiprocessing.cpu_count()
# Divisione dei numeri in parti uguali per ciascun processo
chunk_size = len(numbers_to_process) // num_processes
chunks = [numbers_to_process[i:i+chunk_size] for i in range(0, len(numbers_to_process), chunk_size)]
# Creazione di un array condiviso per memorizzare i risultati
result_array = multiprocessing.Array('d', len(numbers_to_process))
# Creazione di processi multipli per calcolare le radici quadrate in parallelo
processes = []
for i, chunk in enumerate(chunks):
process = multiprocessing.Process(target=square_root, args=(chunk, result_array, i * chunk_size))
processes.append(process)
process.start()
# Attendi il completamento di tutti i processi
for process in processes:
process.join()
# Stampare alcuni risultati di esempio
print("Radice quadrata dei primi 10 numeri:", [result_array[i] for i in range(10)])
In questo esempio:
Creiamo una lista di numeri di esempio da 1 a 1 milione.
Dividiamo questa lista in parti uguali, ognuna delle quali sarà elaborata da un processo separato.
Utilizziamo il modulo multiprocessing per creare e avviare più processi, ciascuno dei quali calcola la radice quadrata dei numeri assegnati.
Ognuno dei processi elabora una porzione dei dati e memorizza i risultati in un array condiviso.
Infine, uniamo tutti i risultati e ne stampiamo alcuni per mostrare l'output.
Questo esempio illustra come dividere un'attività di elaborazione su grandi quantità di dati in parti più piccole che possono essere elaborate simultaneamente, sfruttando il parallelismo dei dati per accelerare il processo complessivo.
12.2-Parallelismo delle attività o dei task: Suddivide il problema in diversi task indipendenti che possono essere eseguiti simultaneamente. Questi task possono interagire tra loro solo quando necessario. Ad esempio, in un'applicazione web, diverse richieste degli utenti possono essere gestite da thread o processi separati.
Il parallelismo delle attività o dei task coinvolge l'esecuzione simultanea di diverse operazioni o task, ciascuno dei quali viene eseguito indipendentemente dagli altri. Un esempio comune di parallelismo delle attività può essere ottenuto utilizzando librerie come concurrent.futures in Python.
Qui di seguito un esempio di come eseguire diverse attività in parallelo utilizzando concurrent.futures.ThreadPoolExecutor:
python
Copy code
import concurrent.futures
import time
# Funzione che esegue un'attività (simulazione di un'operazione di lunga durata)
def task(task_id):
print(f"Task {task_id} iniziato")
# Simulazione di un'operazione di lunga durata
time.sleep(3)
print(f"Task {task_id} completato")
if __name__ == "__main__":
# Numero di attività da eseguire
num_tasks = 5
# Creazione di un ThreadPoolExecutor con un massimo di 3 thread
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
# Esecuzione delle attività in parallelo
executor.map(task, range(num_tasks))
In questo esempio:
Definiamo una funzione task che simula un'operazione di lunga durata. Ogni task dorme per 3 secondi per simulare un'elaborazione complessa.
Utilizziamo concurrent.futures.ThreadPoolExecutor per creare un pool di thread con una dimensione massima di 3 thread.
Utilizziamo il metodo executor.map per mappare la funzione task a una sequenza di valori (in questo caso, una sequenza di numeri da 0 a 4), eseguendo così simultaneamente i task in parallelo.
Questo esempio dimostra come è possibile eseguire diverse attività in parallelo utilizzando un pool di thread, permettendo a ciascuna attività di essere eseguita indipendentemente e contemporaneamente alle altre. Il parallelismo delle attività può essere utile per migliorare l'efficienza quando si gestiscono più compiti concorrenti che possono essere eseguiti in modo indipendente.
12.3-Parallelismo di istruzione: Sfrutta l'architettura dei processori moderni che possono eseguire più istruzioni simultaneamente. Questo approccio cerca di massimizzare l'efficienza dell'elaborazione parallela su un singolo processore.
Il parallelismo di istruzione si riferisce alla capacità di eseguire più istruzioni in parallelo, suddividendo un compito in istruzioni più piccole che possono essere eseguite contemporaneamente. In Python, il GIL (Global Interpreter Lock) impedisce l'esecuzione di più istruzioni Python simultaneamente all'interno dello stesso processo Python a causa di vincoli di concorrenza. Tuttavia, il modulo multiprocessing può essere utilizzato per eseguire codice parallelo su più processi.
Ecco un esempio di come potresti utilizzare il modulo multiprocessing per eseguire operazioni matematiche parallele su più processi:
python
Copy code
import multiprocessing
# Funzione per calcolare la radice quadrata di un numero
def square_root(number):
return number ** 0.5
if __name__ == "__main__":
# Lista di numeri di esempio
numbers = [x for x in range(1, 11)]
# Creazione di un pool di processi
with multiprocessing.Pool() as pool:
# Applicazione parallela della funzione square_root ai numeri utilizzando il pool di processi
results = pool.map(square_root, numbers)
# Stampare i risultati
print("Radici quadrate:", results)
In questo esempio:
Definiamo una funzione square_root che calcola la radice quadrata di un numero.
Creiamo una lista di numeri di esempio da 1 a 10.
Utilizziamo multiprocessing.Pool() per creare un pool di processi.
Utilizziamo il metodo pool.map() per applicare la funzione square_root a ciascun numero nella lista in parallelo, utilizzando il pool di processi.
Otteniamo i risultati delle operazioni parallele.
Il parallelismo di istruzione, in questo caso, è ottenuto attraverso l'esecuzione delle operazioni matematiche su più processi in parallelo, permettendo a ciascun processo di eseguire istruzioni indipendenti contemporaneamente, migliorando così l'efficienza complessiva dell'esecuzione delle operazioni matematiche.
Gli algoritmi paralleli sono utilizzati in diversi ambiti:
Calcolo scientifico: Risolve problemi complessi come simulazioni fisiche, modelli climatici, analisi di grandi dataset, ecc.
Elaborazione distribuita: Utilizza più computer collegati in rete per eseguire un lavoro condiviso, come ad esempio nell'elaborazione di grandi moli di dati o nell'esecuzione di calcoli complessi distribuiti su più nodi di una rete.
Alcuni esempi di paradigmi paralleli includono MapReduce (usato da framework come Hadoop per l'elaborazione distribuita), parallelismo di thread in linguaggi di programmazione multi-threading come Java o Python, calcolo parallelo su GPU (Graphics Processing Unit) e altro ancora.
L'utilizzo di algoritmi paralleli dipende dalla natura del problema, dalla disponibilità di risorse parallele e dalla capacità di progettazione di algoritmi che possano sfruttare efficacemente il potenziale di calcolo parallelo offerto da sistemi multi-core o distribuiti.

Gli algoritmi di apprendimento automatico (Machine Learning) costituiscono un insieme di tecniche e metodologie che consentono ai computer di apprendere dai dati senza essere esplicitamente programmati per compiti specifici. Questi algoritmi sono ampiamente utilizzati per analizzare dati, riconoscere pattern, fare previsioni o prendere decisioni basate sui dati.
Ecco alcuni esempi di algoritmi di machine learning comunemente utilizzati:
11.1-Reti Neurali Artificiali: Questi modelli sono ispirati al funzionamento del cervello umano e sono costituiti da strati di neuroni artificiali collegati tra loro. Le reti neurali possono essere utilizzate per compiti di classificazione, regressione, elaborazione del linguaggio naturale, computer vision, ecc.
Ecco un esempio di implementazione di una semplice rete neurale artificiale utilizzando la libreria TensorFlow in Python. In questo esempio, creeremo una rete neurale per risolvere un problema di classificazione utilizzando il dataset Iris.
python
Copy code
import tensorflow as tf
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
# Caricamento del dataset Iris
iris = load_iris()
X = iris.data
y = iris.target.reshape(-1, 1)
# Codifica one-hot per le etichette
encoder = OneHotEncoder(sparse=False)
y = encoder.fit_transform(y)
# Divisione del dataset in set di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creazione del modello di rete neurale
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=(X.shape[1],), activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
# Compilazione del modello
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Addestramento della rete neurale
model.fit(X_train, y_train, epochs=100, batch_size=32, verbose=1, validation_data=(X_test, y_test))
# Valutazione delle prestazioni del modello
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Loss: {loss}, Accuracy: {accuracy}')
In questo esempio:
Carichiamo il dataset Iris utilizzando scikit-learn.
Codifichiamo le etichette in un formato one-hot utilizzando OneHotEncoder di scikit-learn.
Dividiamo il dataset in set di addestramento e test.
Creiamo un modello sequenziale utilizzando TensorFlow Keras, composto da uno strato nascosto con 10 neuroni e uno strato di output con 3 neuroni (corrispondenti alle classi del dataset Iris) e attivazione softmax.
Compiliamo il modello specificando l'ottimizzatore, la funzione di loss e le metriche da monitorare durante l'addestramento.
Addestriamo il modello sui dati di addestramento per 100 epoche con un batch size di 32.
Valutiamo le prestazioni del modello utilizzando i dati di test.
Questo è solo un esempio semplice di come si può implementare una rete neurale per la classificazione utilizzando TensorFlow in Python. Le reti neurali possono essere configurate in molti modi diversi con diversi strati, funzioni di attivazione, ottimizzatori e parametri, a seconda del problema specifico da risolvere.
11.2-Alberi Decisionali: Sono modelli che strutturano decisioni in forma di albero, suddividendo iterativamente i dati in base a determinate variabili. Sono usati per problemi di classificazione e regressione.
Esempio di utilizzo degli alberi decisionali per la classificazione utilizzando la libreria scikit-learn in Python:
python
Copy code
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
# Caricamento del dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Divisione del dataset in set di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creazione del classificatore ad albero decisionale
clf = DecisionTreeClassifier(random_state=42)
# Addestramento del modello
clf.fit(X_train, y_train)
# Predizione sui dati di test
predictions = clf.predict(X_test)
# Valutazione delle prestazioni del modello
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}\n')
# Report di classificazione
print('Classification Report:')
print(classification_report(y_test, predictions))
In questo esempio:
Carichiamo il dataset Iris utilizzando scikit-learn.
Dividiamo il dataset in set di addestramento e test.
Creiamo un classificatore ad albero decisionale utilizzando DecisionTreeClassifier di scikit-learn.
Addestriamo il modello sul set di addestramento utilizzando il metodo fit.
Effettuiamo previsioni sul set di test utilizzando il metodo predict.
Valutiamo le prestazioni del modello stampando l'accuratezza e generando un report di classificazione che include precision, recall, f1-score e support per ciascuna classe.
Gli alberi decisionali sono modelli semplici e interpretabili che operano suddividendo ricorsivamente il dataset in base alle caratteristiche che meglio separano le classi di destinazione. Sono utilizzati sia per problemi di classificazione che di regressione, e possono essere utilizzati in diversi contesti grazie alla loro interpretabilità e capacità di gestire dati categorici e numerici.
11.3-Support Vector Machines (SVM): È un algoritmo di apprendimento supervisionato che cerca di trovare il miglior iperpiano di separazione tra i dati appartenenti a classi diverse nello spazio multidimensionale.
Esempio di utilizzo delle Support Vector Machines (SVM) per la classificazione utilizzando la libreria scikit-learn in Python:
python
Copy code
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# Caricamento del dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Divisione del dataset in set di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creazione del classificatore SVM
svm_classifier = SVC(kernel='linear', random_state=42)
# Addestramento del modello
svm_classifier.fit(X_train, y_train)
# Predizione sui dati di test
predictions = svm_classifier.predict(X_test)
# Valutazione delle prestazioni del modello
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}\n')
# Report di classificazione
print('Classification Report:')
print(classification_report(y_test, predictions))
In questo esempio:
Carichiamo il dataset Iris utilizzando scikit-learn.
Dividiamo il dataset in set di addestramento e test.
Creiamo un classificatore SVM utilizzando SVC di scikit-learn con un kernel lineare.
Addestriamo il modello sul set di addestramento utilizzando il metodo fit.
Effettuiamo previsioni sul set di test utilizzando il metodo predict.
Valutiamo le prestazioni del modello stampando l'accuratezza e generando un report di classificazione che include precision, recall, f1-score e support per ciascuna classe.
Le Support Vector Machines sono modelli di apprendimento supervisionato che possono essere utilizzati sia per problemi di classificazione che di regressione. L'obiettivo principale di SVM è trovare l'iperpiano ottimale che meglio separa le classi nel dataset. SVM può utilizzare diversi tipi di kernel (lineare, polinomiale, RBF, ecc.) per gestire diversi tipi di problemi di classificazione. Nell'esempio sopra, viene utilizzato un kernel lineare, ma è possibile sperimentare con altri kernel per ottenere prestazioni ottimali in base al dataset e al problema specifico.
11.4-Random Forest: È una tecnica che costruisce più alberi decisionali e combina le loro previsioni per ottenere una previsione più accurata e ridurre l'overfitting.
Ecco un esempio di utilizzo di Random Forest per la classificazione utilizzando la libreria scikit-learn in Python:
python
Copy code
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# Caricamento del dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Divisione del dataset in set di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creazione del classificatore Random Forest
random_forest = RandomForestClassifier(n_estimators=100, random_state=42)
# Addestramento del modello
random_forest.fit(X_train, y_train)
# Predizione sui dati di test
predictions = random_forest.predict(X_test)
# Valutazione delle prestazioni del modello
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}\n')
# Report di classificazione
print('Classification Report:')
print(classification_report(y_test, predictions))
In questo esempio:
Carichiamo il dataset Iris utilizzando scikit-learn.
Dividiamo il dataset in set di addestramento e test.
Creiamo un classificatore Random Forest utilizzando RandomForestClassifier di scikit-learn con 100 alberi nell'insieme.
Addestriamo il modello sul set di addestramento utilizzando il metodo fit.
Effettuiamo previsioni sul set di test utilizzando il metodo predict.
Valutiamo le prestazioni del modello stampando l'accuratezza e generando un report di classificazione che include precision, recall, f1-score e support per ciascuna classe.
Random Forest è un modello di apprendimento ensemble che combina più alberi decisionali durante l'addestramento. Ogni albero decisionale viene addestrato su un sottoinsieme casuale dei dati e produce una previsione. La previsione finale del Random Forest è ottenuta combinando le previsioni di tutti gli alberi. Questa tecnica di ensemble spesso porta a migliori prestazioni e generalizzazione rispetto a un singolo albero decisionale. La flessibilità di Random Forest lo rende utile per vari problemi di classificazione e regressione.
11.5-K-Nearest Neighbors (K-NN): Un algoritmo di classificazione che classifica un oggetto basandosi sulla maggioranza dei voti dei suoi vicini più vicini nel dataset.
Ecco un esempio di utilizzo dell'algoritmo K-Nearest Neighbors (K-NN) per la classificazione utilizzando la libreria scikit-learn in Python:
python
Copy code
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
# Caricamento del dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Divisione del dataset in set di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creazione del classificatore K-NN con K=3
knn_classifier = KNeighborsClassifier(n_neighbors=3)
# Addestramento del modello
knn_classifier.fit(X_train, y_train)
# Predizione sui dati di test
predictions = knn_classifier.predict(X_test)
# Valutazione delle prestazioni del modello
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}\n')
# Report di classificazione
print('Classification Report:')
print(classification_report(y_test, predictions))
In questo esempio:
Carichiamo il dataset Iris utilizzando scikit-learn.
Dividiamo il dataset in set di addestramento e test.
Creiamo un classificatore K-Nearest Neighbors (K-NN) utilizzando KNeighborsClassifier di scikit-learn con K=3, cioè considerando i 3 vicini più prossimi.
Addestriamo il modello sul set di addestramento utilizzando il metodo fit.
Effettuiamo previsioni sul set di test utilizzando il metodo predict.
Valutiamo le prestazioni del modello stampando l'accuratezza e generando un report di classificazione che include precision, recall, f1-score e support per ciascuna classe.
K-Nearest Neighbors è un algoritmo di apprendimento supervisionato utilizzato sia per problemi di classificazione che di regressione. Il principio di base dell'algoritmo K-NN consiste nel classificare un punto di dati basandosi sui voti della maggioranza dei suoi "K" vicini più prossimi nel set di addestramento. La scelta di un valore appropriato di K è importante e può influenzare le prestazioni del modello.
11.6-Algoritmi di clustering (come K-Means): Usati per raggruppare insieme dati simili in base a determinate caratteristiche senza alcuna supervisione.
Ecco un esempio di utilizzo dell'algoritmo K-Means per il clustering utilizzando la libreria scikit-learn in Python:
python
Copy code
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Generazione di dati casuali con 4 cluster
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# Creazione del modello K-Means per 4 cluster
kmeans = KMeans(n_clusters=4)
# Addestramento del modello
kmeans.fit(X)
# Predizione dei cluster per ciascun punto
predicted_clusters = kmeans.predict(X)
# Estrazione dei centroidi dei cluster
centroids = kmeans.cluster_centers_
# Visualizzazione dei punti e dei centroidi dei cluster
plt.scatter(X[:, 0], X[:, 1], c=predicted_clusters, cmap='viridis', s=50, alpha=0.7)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='o', c='red', s=200, edgecolors='k')
plt.title('Clustering utilizzando K-Means')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
In questo esempio:
Generiamo dati casuali utilizzando la funzione make_blobs di scikit-learn con 4 cluster.
Creiamo un modello K-Means specificando di voler individuare 4 cluster utilizzando KMeans di scikit-learn.
Addestriamo il modello K-Means utilizzando il metodo fit sui dati generati.
Utilizziamo il modello addestrato per predire il cluster a cui appartiene ciascun punto dati.
Estraiamo i centroidi dei cluster trovati.
Visualizziamo i dati con i relativi cluster assegnati e i centroidi dei cluster.
K-Means è un popolare algoritmo di clustering che suddivide un insieme di dati in un numero prestabilito di cluster (specificato dall'utente) in base alla similarità delle caratteristiche dei dati. L'algoritmo cerca di minimizzare la somma dei quadrati delle distanze tra i punti dati e i centroidi dei cluster, assegnando ciascun punto al cluster con il centroide più vicino.
11.7-Algoritmi di riduzione della dimensionalità (come PCA, Principal Component Analysis): Utilizzati per ridurre la complessità dei dati mantenendo le caratteristiche più importanti.
Ecco un esempio di utilizzo dell'algoritmo PCA (Principal Component Analysis) per la riduzione della dimensionalità utilizzando la libreria scikit-learn in Python:
python
Copy code
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Caricamento del dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Applicazione di PCA per ridurre la dimensionalità a 2 componenti principali
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# Plot dei dati ridotti a 2 dimensioni
plt.figure(figsize=(8, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', edgecolor='k')
plt.title('Riduzione della dimensionalità con PCA')
plt.xlabel('Componente Principale 1')
plt.ylabel('Componente Principale 2')
plt.colorbar(label='Classe')
plt.show()
In questo esempio:
Carichiamo il dataset Iris utilizzando scikit-learn.
Applichiamo l'algoritmo PCA per ridurre la dimensionalità dei dati originali a 2 componenti principali utilizzando PCA di scikit-learn.
Utilizziamo il metodo fit_transform per addestrare il modello PCA e trasformare i dati originali nelle nuove dimensioni.
Visualizziamo i dati ridotti a 2 dimensioni utilizzando uno scatter plot, dove i punti sono colorati in base alla classe.
PCA è una tecnica di riduzione della dimensionalità che cerca di proiettare i dati originali in un nuovo spazio delle caratteristiche in modo che la varianza sia massimizzata lungo i primi componenti principali. In questo esempio, riduciamo le quattro dimensioni dei dati Iris a soli due per poterli visualizzare graficamente, ma PCA può essere utilizzato anche per ridurre la dimensionalità per scopi di analisi dei dati o di riduzione del rumore nelle informazioni.
Questi sono solo alcuni esempi, ma ci sono molte altre tecniche e algoritmi di machine learning utilizzati per svariati scopi, a seconda del tipo di problema e dei dati disponibili. L'efficacia di ciascun algoritmo può variare a seconda del contesto e dei requisiti specifici dell'applicazione o del problema che si sta affrontando.